

Liquid handling robots simplify sample preparations and enable increased throughput in laboratory settings. A side effect of this increase is that they create a new problem, a lot of data. What is a scientist or engineer to do with this data? How can an application specialist extract and store data from a liquid handling robot? The Hamilton STAR Venus software has the native ability to create mapping files and to write that data to output files and/or databases!
Any liquid handler should be producing a log file at the end of a run which will contain the data of what happened somewhere in it. Locating and storing these files somewhere safe as well as entering them into a laboratory notebook should be performed, but this is the bare minimum and we can do better if we know the commands.
Log files are often long text files which while searchable are not very user friendly and it will take significant time to pull out details if the method run was complex (IE multi-step dilutions, cherry picking and reformatting, sample concentration normalization, etc). Using the file and mapping commands we’ll be able to curate just the data we want and store it in an easy to query database structure as well as create user friendly output files.
File Commands
In Venus there are a set of general file commands (open, read, write, close) which an app specialist supporting a Hamilton liquid handler should be familiar with. These commands can be used to create a Microsoft Excel sheet, a structured text file such as a csv, or they can even be used to connect directly to a database such as SQL or Microsoft Access. With these commands you can create a new file or open an existing file or database table and then append new data to it. All of which makes Hamilton STAR data handling easier.
It is important to know that when you open the file it will be considered in use by Windows until the File: Close command is run so don’t forget to do that or have it in your On Abort submethod, just in case. Personally I like to write my data at the end of manipulation of each destination plate at the bottom of my loop before I return to the top and start on the next plate of the sequence but in theory it could be done at the end of each single pipetting step or just at the end of your method.
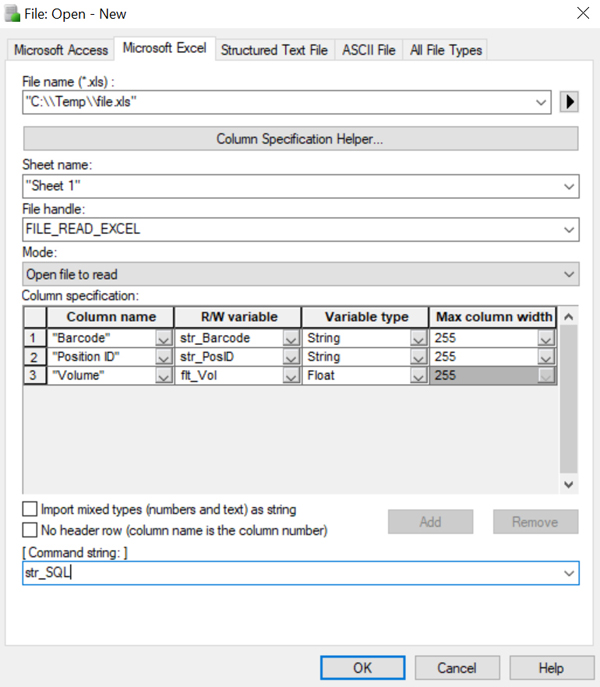
The File Open step for some common file types and what the format should look like.

The File Open step for some common file types and what the format should look like.
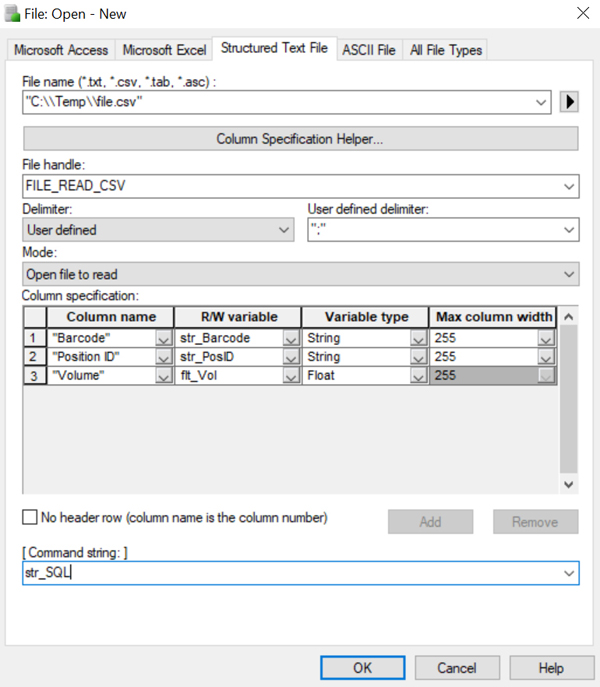
The File Open step for some common file types and what the format should look like.
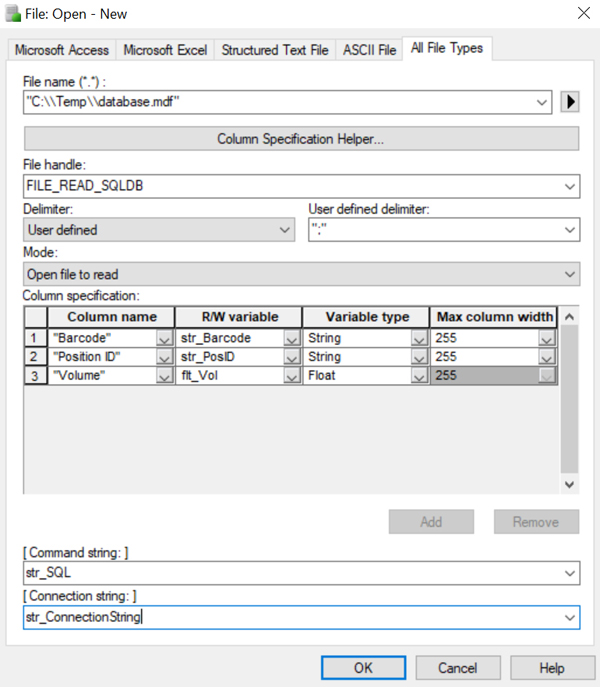
The File Open step for some common file types and what the format should look like.
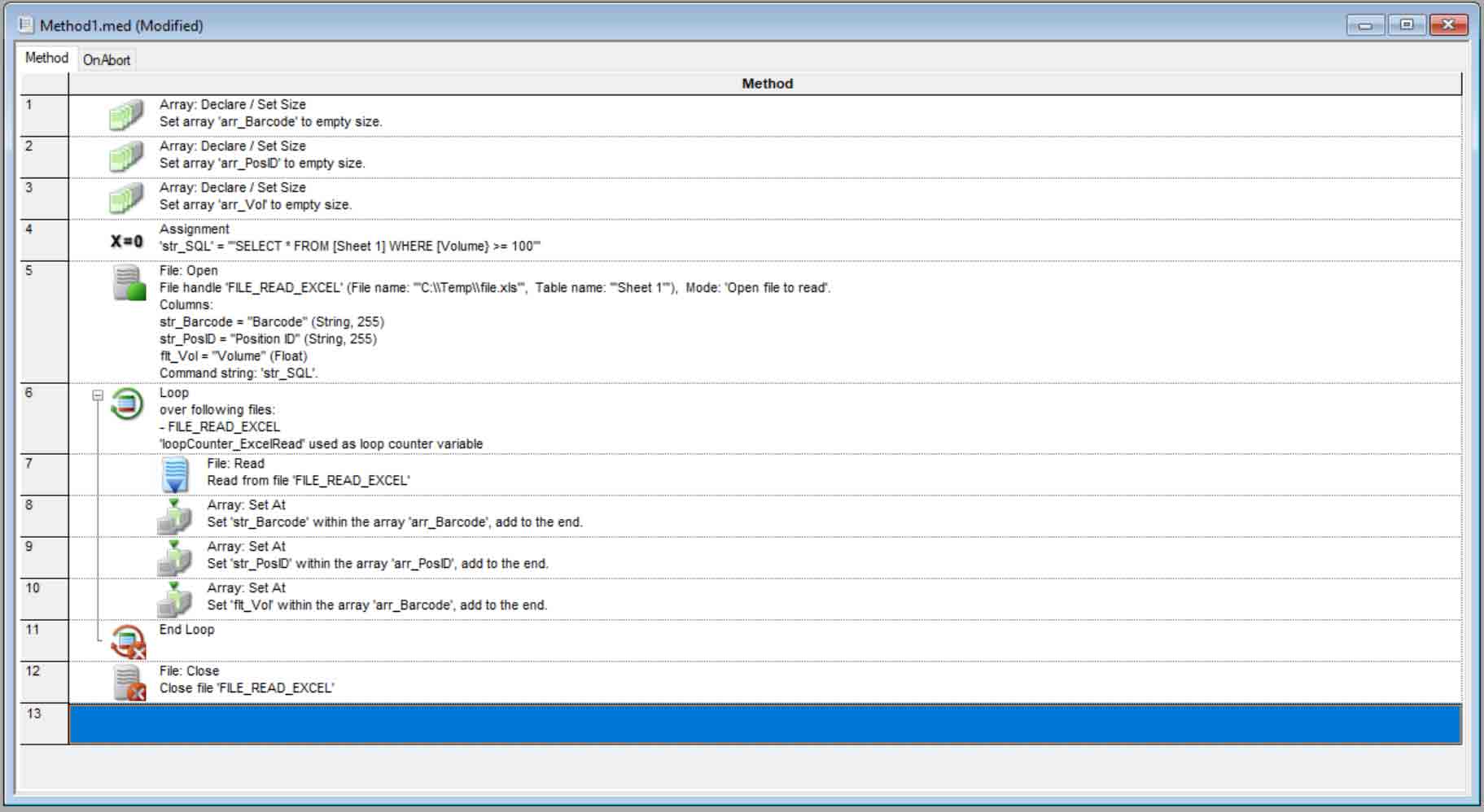
Mapping File Commands
Another command that an app specialist should be familiar with is the create mapping file command. You’ll need to enable the Hamilton STAR Data Handling Steps for your method for this commands to show up in your toolbox, go to Method – Instruments and Smart Steps and then check the box. This command allows you to select a sequence and then the sequence to filter it by, limiting the data to just what you want.
Imagine that you have a destination plate that is filled during your method with three separate reagents before the sample from your source plate is added. Let us say that for the purposes of your record keeping you just want to know the barcode and well locations of the source sample and final destination. While you can make a mapping file of the destination plate it will contain the data of all pipetting steps that involved it, including the reagents.
You can filter this mapping file by the source sample sequence and then you will have a record of just the transfer of the two sequences and the status of that action, a much cleaner and easier to use file.
Of course you could also create four mapping files, one for each of the reagents and the source samples of interest. Since these files are .xls files they are quite easy to iterate over with the File: Read commands and then use an additional File: Write command directed to a final user friendly output file or record that data into your database for long term storage.
Your regulatory and informatics friends will welcome the database storage and your end users will welcome a clean output file that is easy to read and formatted to paste into a paper notebook or upload to an electronic lab notebook.

The Generate Mapping File Command of seq_Destination filtered by seq_Source and the Customize window and settings.

The Generate Mapping File Command of seq_Destination filtered by seq_Source and the Customize window and settings.

Considerations For Your Method
Now there are some things you should consider when adding this functionality to your methods.
- What data do you need to store? More is not always better, store the data that is pertinent and useful. If your method records the lot number of the diluent used but it only allows for a single diluent to be added to all wells then recording that for every well in your destination plate probably isn’t worth while. In addition recording the volumes of liquid used during your mix steps is likely to be of significantly less value than the transferred volume at the end.
- When designing a database think about the design before you start adding commands. Keep like data with like and try not to make too many tables. If you have a database that supports seven methods for a process and you track liquid transfers between them all instead of having seven liquid transfer tables it is much more efficient and easier to maintain to have a single liquid tracking table and a column with a unique identifier for each method. You don’t know what methods you will need to write in the future, if you make a universal design for your tables you can likely continue to use them for future methods.
- For user output files talk to your users and make sure you understand their needs. A short conversation with them on what pieces of data they need access to and the priority of those will allow you to simplify what you are providing them while optimizing the efficiency and usefulness for them. If using Excel you can even create formatted template files and use simple cmd commands to copy them prior to your File: Write commands.
- Finally make sure you understand the regulatory requirements for what you are doing. Do you work in a GxP lab setting? If so make sure your quality assurance or regulatory groups are aware of what you are proposing to add to your methods prior to starting work. You don’t want to sink time into something that can’t actually be used the way you intended.
Of course this is simply a quick primer on some of the options for handling the problem you created in your lab by automating sample preparations and increasing throughput. If you have questions about Hamilton STAR data handling feel free to hit us up in the comments or on our message boards.



Hello.
First, I really appreciated your article. It’s hard to find information about Hamilton Venus software.
I’m trying to track sequences between runs by finishing each method by writing an output file with the current sequence for all labware used in that method. I have an input Excel file that determines the sequences to be used in the method that I would like to open and append with these data. I’m running into issues getting ‘File: Open’ set with ‘Open to append’ and ‘File: Write’ to work in my method and wondered if you have any suggestions.
Thanks,
Kate
Hi Kate,
I’m glad you liked the article and I completely agree that finding information online for Venus is difficult it’s one of the reasons we decided to launch RaveRobot.
As to your question, do you get any error messages or does the data just not show up in the file?
You mentioned you are using an Excel file as an input, are you opening the file to read first and not closing it before trying to open it again to append?
The file commands are also extremely sensitive to the column names and the variable types you are telling them to use. I’ve seen a lot of people accidentally have a typo in the column name or sheet name or also try to write a string out as a float or something, all of which will prevent the command from working.
Also a useful tip, if you are ever using a .csv file and your column name has a period in it, in the File:Open command that needs to be replaced with a #. (Ex a column called “Plate.Barcode” in the csv file would need to be “Plate#Barcode” in the File:Open command.
If the data file has 0 / N/A or EMPTY value in the cell, how can we skip or eliminate that row?
Thanks
Hi Crystall,
You could wrap the File:Read command in an error handling by user and have it just do nothing in the event of an error. When you hit an erroneous line it would just skip it and keep on going. Unfortunately when you define File:Open you tell it what the variable type is (in your case I’m assuming an int or float) and then when you pull the “N/A” it’s not that type so you get a type mismatch.
The other option would be to set it as a string, pull the value and write an if statement that runs if the value is not “N/A” or “Empty” and then use the string library to convert it back to an int or float. It’s a bit backwards but it works.